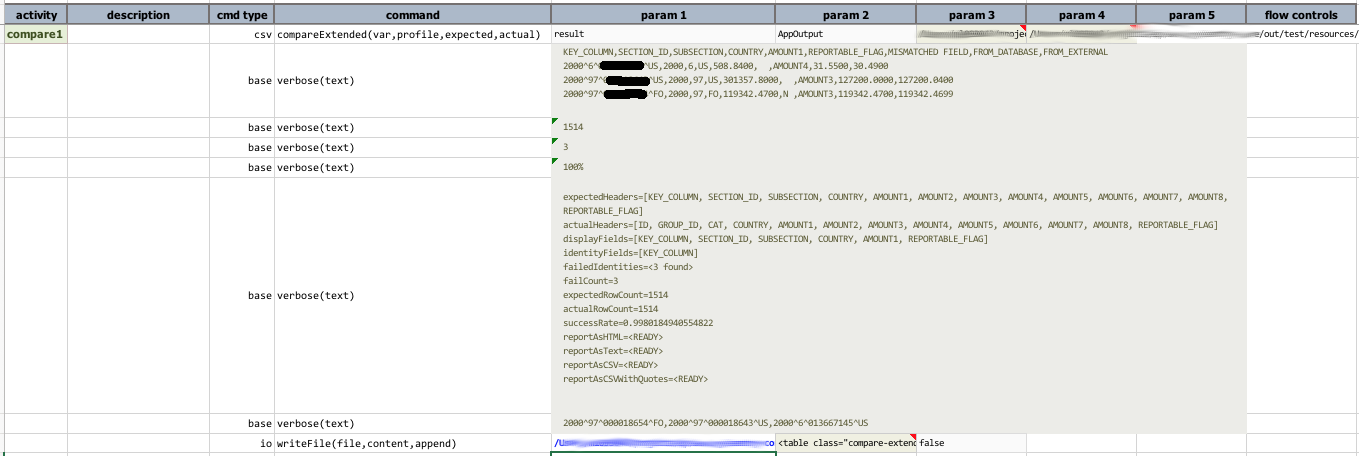
csv » compareExtended(var,profile,expected,actual)
Description
This command provides a more comprehensive way of comparing CSV content. For simple comparison, check out
compare(expected,actual,failFast).
The main purpose of this command is to provide flexibility and insights into the comparison of 2 CSV content with the following strategies:
- Ability to compare 2 fields with different name, and possibly different position in the respective files
- Ability to skip certain fields, but still have them as part of output
- Ability to compare files with disparate sort order
- Ability to specify multiple columns as “identity” columns for fast comparisons
- Ability to generate different format of output, such as CSV and HTML
- Ability to control the fields to display as part of output
- Ability to create reusable configuration for comparison
This command takes 4 parameters:
var- the variable to reference the comparison result (see below for possible data extraction)profile- the reference to the configuration of this comparisonexpected- the file or CSV content that represents the expected contentactual- the file or CSV content that represents the actual content
It is important to note that the expected is treated as the “baseline” - meaning, the subject to compare against.
In comparison, the actual is the “variant”, so as speak.
The profile refers to a set of data variables that are used as configuration for a given comparison. This profile
may be reused for multiple comparisons, thus could be a time saver. The general structure of the comparison
configuration is as follows:
[profile].compareExt.configuration_key | value
Here are the list of possible configuration (assuming the profile is MyFiles):
| configuration | value | notes |
|---|---|---|
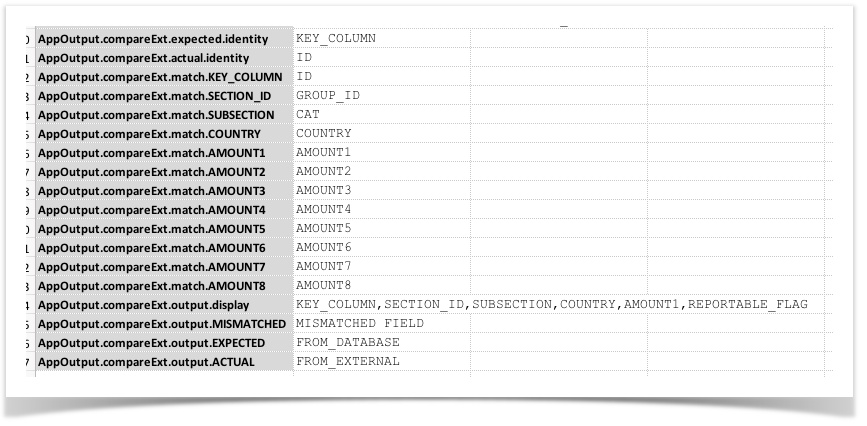
MyFiles.compareExt.expected.identity |
"ID" column name(s) of the expected file. |
REQUIRED The "ID" columns are used in 2 ways:
|
MyFiles.compareExt.actual.identity |
"ID" column name(s) of the actual file. |
REQUIRED see above. |
MyFiles.compareExt.identity.delim |
Default: ^ |
The delimiter to use when multiple identity columns are specified. Default is ^. |
MyFiles.compareExt.match.[EXPECTED COLUMN] |
The corresponding column name of the actual file. |
Specifying the columns to match between the expected and actual file. For example: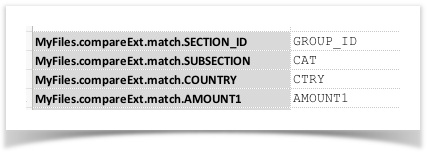 One can specify all the columns to ensure proper matching. If the MyFiles.compareExt.match.[FIELD]
configuration is used then those not specified will be omitted for comparison. If both files contains the exact
same headers, such configuration can be omitted entirely.
|
MyFiles.compareExt.ignore |
The column(s) to ignore for comparison. |
Specifying the column(s) to ignore during field-by-field matching. Multiple columns are separated by
${nexial.textDelim}. The columns are
based on those specified in the expected file. If a "ignore" column is mapped to a different column on the
actual field (via the ...compareExt.match.... configuration), then the mapped column of the actual
field will be ignored as well. If the "ignore" column is not mapped, then Nexial assumes that the same column
on both the expected and actual files.Note that ignoring one or more columns for matching does not preclude them to be used as part of the comparison result. This means that one can specify a column to be ignored for comparison, but use the same column in the comparison report (see compareExtended result below) via the [profile].compareExt.output.display configuration (see below).
|
MyFiles.compareExt.matchAsNumber |
The column(s) to compare number. |
Specifying the column(s) that should be compared as numbers. Multiple columns are separated by
${nexial.textDelim}. The columns are
based on those specified in the expected file.Note that if the value in the specified fields - either the ones in the expected file or the corresponding ones in the actual files - cannot be parsed as number, then the default text-based comparison will be used instead. |
MyFiles.compareExt.matchCaseInsensitive |
The column(s) to compare case-insensitively. |
Specifying the column(s) that should be compared as text case-insensitively. Multiple columns are separated by
${nexial.textDelim}. The columns are
based on those specified in the expected file.Note that one may combine this configuration with ...compareExt.matchAutoTrim so that text
comparison can be conducted after the field values are trimmed AND compared case-insensitively.
|
MyFiles.compareExt.matchAutoTrim |
The column(s) to trim before comparison. |
Specifying the column(s) that should be trimmed (both beginning and end of field value) before comparison.
Multiple columns are separated by
${nexial.textDelim}. The columns are
based on those specified in the expected file.Note that one may combine this configuration with ...compareExt.matchCaseInsensitive so that text
comparison can be conducted after the field values are trimmed AND compared case-insensitively.
|
MyFiles.compareExt.matchAsOrderedList |
The column(s) to be compared as order-significant list (aka array) |
Specifying the column(s) that should be compared as order-significant list. "Order-significant" means that the
order of the list items must be observed and matched between the corresponding EXPECTED and ACTUAL columns. This
means that the corresponding column content for both EXPECTED and ACTUAL files must match both in terms of list
items and their respective order. Further customization is possible via ...compareExt.matchAutoTrim where one can request for each
list item to be trimmed prior to comparison so thatApple,Orange,Banana... would be considered the same as Apple, Orange , BananaAlso, one can invoke case insensitive comparison over "list" columns via ...compareExt.matchCaseInsensitive.Multiple columns are separated by ${nexial.textDelim}. The columns are based on
those specified in the expected file. |
MyFiles.compareExt.matchAsUnorderedList |
The column(s) to be compared as order-insignificant list (aka array) |
Specifying the column(s) that should be compared as order-insignificant list. "Order-insignificant" means that the
order of the list items is not considered as part of the comparison. In such case, only the presence of the list
items is considered for comparision. This means thatApple,Orange,Banana... would be considered the same as Apple,Banana,OrangeFurther customization is possible via ...compareExt.matchAutoTrim where one can request for each
list item to be trimmed prior to comparison so thatApple,Orange,Banana... would be considered the same as Apple, Banana , Orange Also, one can invoke case insensitive comparison over "list" columns via ...compareExt.matchCaseInsensitive.Multiple columns are separated by ${nexial.textDelim}. The columns are
based on those specified in the expected file. |
MyFiles.compareExt.list.delim |
The list item delimiter to use when comparing between "list" columns |
Note that this configuration is only applicable for the columns targeted for
...compareExt.matchAsOrderedList or ...compareExt.matchAsUnorderedList.The delimiter specified here will be used to parse the "list" columns prior to comparison. |
MyFiles.compareExt.output.display |
The column(s) - the expected file's perspective - to display as part of output. |
REQUIRED Use this configuration to include or omit certain fields. Not all fields are used for matching. If the MyFiles.compareExt.match.[FIELD] configuration is used then those not specified will be omitted for
comparison. However such omitted fields can still be used for output purpose - via this configuration.
Furthermore, it is possible to alter the order of these columns in the output.
|
MyFiles.compareExt.output.MISMATCHED |
Field name of the "mismatched" field. |
This command provides an additional field to specify where the mismatched is found. This
configuration specify what such field should be called. By default it is MISMATCHED FIELD.
|
MyFiles.compareExt.output.EXPECTED |
Field name of the "mismatched" value from the expected file. |
The field name to use for displaying the value from the expected file for the "mismatched"
field (see above).
|
MyFiles.compareExt.output.ACTUAL |
Field name of the "mismatched" value from the actual file. |
The field name to use for displaying the value from the actual file for the "mismatched" field
(see above).
|
MyFiles.compareExt.expected.readAsIs |
true to read the expected as is; false if otherwise. |
Determine if the expected should be read as is without any token replacement, end-of-line or
character set conversion. This has direct impact to memory footprint (improvement, that is) and is the preferred
choice if the expected content does not contain any data variables (i.e. ${...}). The
default value is false.
|
MyFiles.compareExt.actual.readAsIs |
true to read the actual as is; false if otherwise. |
Determine if the actual should be read as is without any token replacement, end-of-line or
character set conversion. This has direct impact to memory footprint (improvement, that is) and is the preferred
choice if the actual content does not contain any data variables (i.e. ${...}). The
default value is false.
|
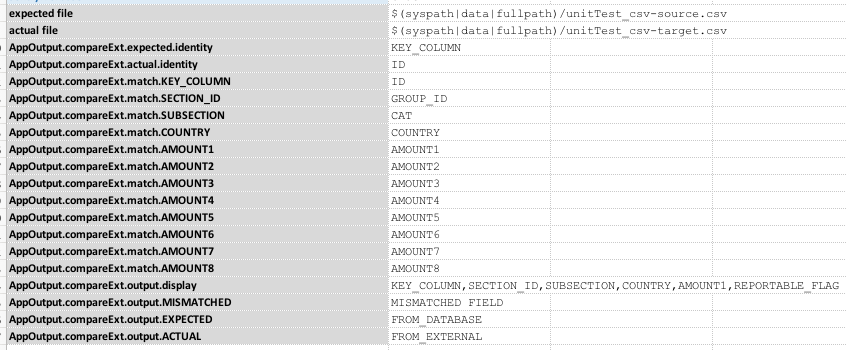
Here’s an example of the comparison configuration (in this case, the profile is AppOutput):
At times one might be working with a unusually long (or wide) CSV file, where the number of expected columns are longer than the default “max” of 512, or column width longer than the default “max” of 4096 character. In such case, one may want to set the following System variables to indicate the need thereof:
nexial.csv.maxColumns: configure the maximum number of columns to expect. The default is 512.nexial.csv.maxColumnWidth: configure the maximum number of character per column. The default is 4096 (characters).
compareExtended result
For output, there are various data elements that are available. Below is a depiction of what one can retrieve from
the comparison result (referenced by the specified var variable):
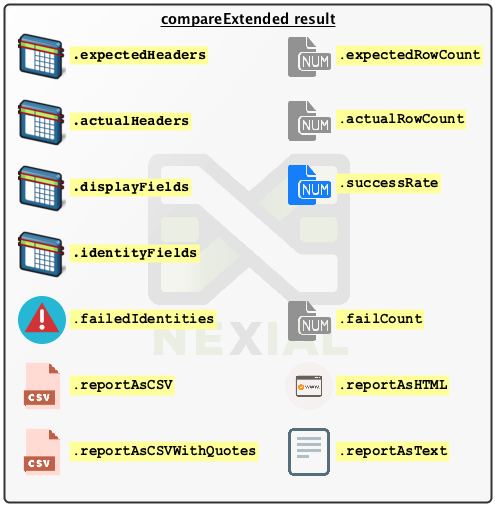
For example, assuming that the var is specified as result:
-
To retrieve the number of mismatched rows -
${result}.failCount - To find the rate of matches -
[NUMBER(${result}.successRate) -> multiple(100) roundTo(00.00)]%- Note that we are using Nexial Expression in the example above to convert a rate of 0 to 1 to a percentage value.
-
To list the identities of the mismatched records -
${result}.failIdentities - To generate a report, in CSV format, of the mismatched records -
${result}.reportAsCSV
- Note that
MISMATCHED FIELDis controlled via theprofile.compareExt.output.MISMATCHEDconfiguration (see above). - Note that
FROM_DATABASErepresents the mismatched field from theexpectedfile, and is controlled via theprofile.compareExt.output.EXPECTEDconfiguration (see above). - Note that
FROM_EXTERNALrepresents the mismatched field from theactualfile, and is controlled via theprofile.compareExt.output.ACTUALconfiguration (see above).
- Note that
-
To generate a comparison report in HTML format, use
${result}.reportAsHTML

The same HTML can be better rendered via external stylesheet. The table DOM has a style class of
compare-extended-result-tablelike so:<table class="compare-extended-result-table"> <thead> <tr> <th>KEY_COLUMN</th> <th>SECTION_ID</th> ... ... </tr> </thead> <tbody> <tr> ... ... ... </tr> </tbody> </table>As such, one can include a stylesheet to create a more appealing presentation for the same HTML report. For example, with the following stylesheet:
table.compare-extended-result-table { font-size: 10pt; color: #333; font-family: monospace; padding: 5px; border: 1px solid #888; border-radius: 5px; box-shadow: 5px 1px 10px #555; } table.compare-extended-result-table thead tr th { font-weight: bold; font-family: sans-serif; text-align: left; text-shadow: 1px 1px 3px #888; color: #358; padding: 0 5px; } table.compare-extended-result-table tbody tr td { border-bottom: 1px solid #ddd; padding: 2px 5px; margin-right: 2px; }One can possibly render the same HTML as:

The above stylesheet is available here - https://nexiality.github.io/documentation/assets/report/csv-compareExtended-report.css One can embedded this stylesheet (or another one) with the generated HTML comparison report like this:
<html> <head> <link rel="stylesheet" href="https://nexiality.github.io/documentation/assets/report/csv-compareExtended-report.css"/> <title>CompareExtended Report - powered by Nexial Automation</title> <style> /* add additional stylesheet here, as per your liking */ body { font-family: Calibri, serif; font-size: 10pt; background-color: #fff; } </style> </head> <body> ... ... *** INSERT THE GENERATED HTML COMPARISION REPORT HERE *** ... ... </body> </html>
Note: to generate the HTML (like the one above) dynamically, one can consider using the
io » writeFile(file,content,append) command. By setting append as true, the HTML
content can be “build up” over multiple commands.
Parameters
see above for parameter details
Example
Script:

Data file:
Output: