LIST
Description
LIST represents expression intended to transform/manipulate a list of things. This expression starts by specifying
a list separated by nexial.textDelim
For example:

Here, we are forcing nexial.textDelim as comma (,), although it is unlikely necessary. Then we set myList to
a list of US states. The last command uses a LIST expression to sort the US states. Here’s the output:

Example
Suppose we want to sum up a list of numbers (In this example, we are not considering currency conversion):
- €28,782.00
- €28,901.23
- €31,234.56
- $29,876.54
- €28,567.51
Here’s how one might approach the automation:
Script:

Since the values contains commas (,), we should not consider , as the delimiter (default). Hence the first step is
to substitute , with another delimiter (|).
As an example, we are creating the list of values manually here in Step 2. One might derive at this list of values via of the commands that support LIST such as:
- base »
split(text,delim,saveVar) - excel »
saveData(var,file,worksheet,range) - json »
storeValues(json,jsonpath,var) - web »
saveValues(var,locator) - web »
saveTextArray(var,locator) - xml »
storeValues(xml,xpath,var)
The bulk of the work is in the 3rd step, where we employ multiple operations:
- Replace
,with nothing - effectively removing the,character. Note that,is also the parameter separator - hence the slightly unusual syntaxreplace(\,,). It reads: “replace commas (the escaped comma (\,)) with nothing”. - Replace the
€and$with nothing - effectively removing them. Here we are using thereplaceRegexoperation to remove multiple characters with one operation. As a matter of personal preference, one could use multiplereplaceoperations to achieve the same result. - Now that
,€and$characters have been removed, our values now can be treated as numbers. We can simply apply thesumoperations to derive the total value. Note that after thesumoperation, we have effectively switch from a LIST expression to NUMBER expression. - The NUMBER expression, among other operations, allows for customized numeric rounding. Here we
are rounding the total to 1 decimal place via the
roundTooperation. - Finally we are storing the value to a variable named as
total.
Step 4 shows how the rounded total value can be compared with another numeric value that contains different
decimal precision. Unlike the text-based assertion commands in base, the assertion commands in
number perform numerical comparison so that numbers of different precision may be treated as the
same if they are numerically equivalent.
The output further illustrates the explanation above and confirms the expectation.
Output:

Operations
append(items)
Add the specified items to the end of the current list.
Example
Script:

Output:

ascending
Re-order the list in ascending order, based on the natural lexicographical order.
Example
Script:

Output:

average
Calculate the average of all the numbers found in the list as a NUMBER. Non-numeric items in
the list will be ignored, and not count towards the calculation of the average. In almost all cases, this will be a
decimal number.
Example
In this example, the first step is to remove $ from the myValues variable and then the average
is calculated on the numbers in the list. No need to remove non-numeric values as they are already ignored
while calculating average.
Script:

Here, the average is calculated and stored in result. For rounding off the result, we can use
$(format|number|text|format) or
[NUMBER(...) => roundTo(closestDigit)]. Both the ways are explained in
line 8 and line 9.
Output:

combine(delim)
Same as text, but with customized separator (delim).
Example
Script:

Output:

count
Find the number of items in this list as a NUMBER. Alias to length.
Example
Script:

Output:

descending
Re-order the list in descending order, based on the natural lexicographical order.
Example
Script:

Output:

distinct
Remove all duplicate items in the list.
Example
Script:

Output:

findFirst(match)
Also known as find-first(...). Find the first item in the current list that matches the specified match criteria.
This utilizes polymatcher (below) to determine the matching items. The matched item is returned as a
TEXT expression. If no match is found, null is returned instead.
PolyMatcher - a flexible way to perform text matching
In addition to extract text matching (or string matching), this command/expression also supports "polymatcher" (as of v3.6). With polymatcher, one can instruct Nexial to match the intended text in a less exact (but more expressiveness) way. Here are the supported matching strategies:
-
CONTAIN:: Use this technique to perform partial text matches. For example: useCONTAIN:completedas intent for "matching text that contains the text ‘completed’". -
CONTAIN_ANY_CASE:: Use this technique to perform partial text matches (same asCONTAIN:), except without considering the uppercase/lowercase variants. For example,CONTAIN_ANY_CASE:Successfullywould match "Completed successfully", "Completed Successfully", and "COMPLETED SUCCESSFULLY". -
START:: Use this technique to perform "starts with" text matches. For example,START:Greetingsmatches any text starting with the text "Greetings". -
START_ANY_CASE:: Use this technique to perform "starts with" text matches without considering letter casing. For example,START_ANY_CASE:Greetingsmatches any text starting with the text "Greetings", "GREETINGS", "greetings", "greeTINGs", etc. -
END:: Use this technique to perform "ends with" text matches. For example,END:Please try again.matches any text that ends with the text "Please try again.". -
END_ANY_CASE:: Use this technique to perform "ends with" text matches without considering letter casing. For example,END_ANY_CASE:Please try again.matches any text that ends with the text "Please try again." in any combination of upper or lower case. -
REGEX:: Use this technique to perform text matching via regular expression. For example: useREGEX:.+[S|s]uccessfully.*as intent for "matching text that contains 1 or more character, then either ‘Successfully’ or ‘successfully’, follow by zero or more characters.". -
EMPTY:[true|false]: Use this technique to perform "is empty?" check.EMPTY:truemeans that the target value is expected to be empty (no content or length).EMPTY:falsemeans the target value is expected NOT to be empty (with content). -
BLANK:[true|false]: Use this technique to perform "is blank?" check.BLANK:truemeans that the target value is expected to contain blank(s) or whitespace (space, tab, newline, line feed, etc.) characters or empty (no content or length).BLANK:falsemeans the target value is expected to contain at least 1 non-whitespace character. Note that this matcher includes teEMPTY:check as well. -
LENGTH:: Use this technique to perform text length validation against target value. One may use a numeric comparator for added flexibility/expressiveness. For example:LENGTH:5means to match the target value to a length of 5.LENGTH: > 5means to match the target value to a length greater than 5. The available comparators are:>,>=,<,<=,=,!=. -
NUMERIC:: Use this technique to perform numeric comparison/matching against target value. With this technique,100considered the same as100.00since both value has the same numerical value. One may use a numeric comparator for added flexibility/expressiveness. For example:NUMERIC:5means to match the target value to the number5.NUMERIC: <= -15.02means to match the target value as a number that is less or equal to-15.02. The available comparators are:>,>=,<,<=,=,!=. -
EXACT:: Use this to perform exact text matching, i.e. equality matching. In most cases, this is not required as the absence of any special keyword almost always means the "is this the same as that?" test. However in some special cases such as base »assertMatch(text,regex), one may use thisEXACT:syntax to indicate match by equality instead of regular expression. - And, of course, one can still use the exact matching strategy by specifying the exact text to match.
We will be adding new strategy to polymatcher – Please feel free to request for new ones!
first
Retrieve the first item in the list as a TEXT.
Example
Script:

Output:

index(item)
Transform the current list to a NUMBER representing the position of the specified item in the
list.
PolyMatcher - a flexible way to perform text matching
In addition to extract text matching (or string matching), this command/expression also supports "polymatcher" (as of v3.6). With polymatcher, one can instruct Nexial to match the intended text in a less exact (but more expressiveness) way. Here are the supported matching strategies:
-
CONTAIN:: Use this technique to perform partial text matches. For example: useCONTAIN:completedas intent for "matching text that contains the text ‘completed’". -
CONTAIN_ANY_CASE:: Use this technique to perform partial text matches (same asCONTAIN:), except without considering the uppercase/lowercase variants. For example,CONTAIN_ANY_CASE:Successfullywould match "Completed successfully", "Completed Successfully", and "COMPLETED SUCCESSFULLY". -
START:: Use this technique to perform "starts with" text matches. For example,START:Greetingsmatches any text starting with the text "Greetings". -
START_ANY_CASE:: Use this technique to perform "starts with" text matches without considering letter casing. For example,START_ANY_CASE:Greetingsmatches any text starting with the text "Greetings", "GREETINGS", "greetings", "greeTINGs", etc. -
END:: Use this technique to perform "ends with" text matches. For example,END:Please try again.matches any text that ends with the text "Please try again.". -
END_ANY_CASE:: Use this technique to perform "ends with" text matches without considering letter casing. For example,END_ANY_CASE:Please try again.matches any text that ends with the text "Please try again." in any combination of upper or lower case. -
REGEX:: Use this technique to perform text matching via regular expression. For example: useREGEX:.+[S|s]uccessfully.*as intent for "matching text that contains 1 or more character, then either ‘Successfully’ or ‘successfully’, follow by zero or more characters.". -
EMPTY:[true|false]: Use this technique to perform "is empty?" check.EMPTY:truemeans that the target value is expected to be empty (no content or length).EMPTY:falsemeans the target value is expected NOT to be empty (with content). -
BLANK:[true|false]: Use this technique to perform "is blank?" check.BLANK:truemeans that the target value is expected to contain blank(s) or whitespace (space, tab, newline, line feed, etc.) characters or empty (no content or length).BLANK:falsemeans the target value is expected to contain at least 1 non-whitespace character. Note that this matcher includes teEMPTY:check as well. -
LENGTH:: Use this technique to perform text length validation against target value. One may use a numeric comparator for added flexibility/expressiveness. For example:LENGTH:5means to match the target value to a length of 5.LENGTH: > 5means to match the target value to a length greater than 5. The available comparators are:>,>=,<,<=,=,!=. -
NUMERIC:: Use this technique to perform numeric comparison/matching against target value. With this technique,100considered the same as100.00since both value has the same numerical value. One may use a numeric comparator for added flexibility/expressiveness. For example:NUMERIC:5means to match the target value to the number5.NUMERIC: <= -15.02means to match the target value as a number that is less or equal to-15.02. The available comparators are:>,>=,<,<=,=,!=. -
EXACT:: Use this to perform exact text matching, i.e. equality matching. In most cases, this is not required as the absence of any special keyword almost always means the "is this the same as that?" test. However in some special cases such as base »assertMatch(text,regex), one may use thisEXACT:syntax to indicate match by equality instead of regular expression. - And, of course, one can still use the exact matching strategy by specifying the exact text to match.
We will be adding new strategy to polymatcher – Please feel free to request for new ones!
Example
Script:

Output:

The item must be present in the given list. If item is not present in the list then complete expression is
printed. As it is explained in the above example for script [LIST(${countryList}) => index(japan)]
output is [LIST(china,india,australia,egypt,spain) => index(japan)]. As japan is not present in the list
${countryList}.
insert(index,item)
Insert new item to existing list at position specified by index.
Example
Script:

Output:

When index is greater than the length of the list. Then, output is unable to process expression due to null.

intersect(list)
Transform the current list by creating a new list that contains only the items found in both list. See
Intersection (set theory) for more details.
Example
Script:

Output:

item(indices)
Retrieve the item on the list based on its indices. If invalid indices is specified, an empty string is returned.
This operation supports the retrieval of multiple items as a single TEXT expression. For example:
[LIST(a,b,c,d,e) => item(0,1,4)] would result in the return of a,b,e (first, second, and fifth item).
This operation also supports the retrieval of a list item via random selection. Use random or RANDOM to signify
such intent. For example, [LIST(a,b,c,d,e) => item(random)] or [LIST(a,b,c,d,e) => item(RANDOM)].
Example
Script:

Here, the output of item(8) is empty string as the length of list is 5.
Output:

join(list)
Transform the current list by appending list to it; same as append(items).
Example
Script:

Output:

last
Retrieve the last item in the list as a TEXT.
Example
Script:

Output:

length
Find the length of this list as a NUMBER. Alias to count.
Example
Script:

Output:

max
Find the largest number in the list as a NUMBER.
Example
Script:

Output:

min
Find the smallest number in the list as a NUMBER.
Example
Script:

Output:

pack
Remove all empty or null items in the list.
Example
Script:

Output:

prepend(items)
Add the specified items to the beginning of the current list.
Example
Script:

Output:

remove(index)
Remove an item of the list denoted by the item’s index.
Example
Script:

Output:

removeItems(items)
Remove one or more items from the list.
Example
Script:

Output:

removeMatch(match)
Remove one or more items from the list based on specified match criteria. This operation utilizes polymatcher (below)
to determine the matching items. The result is a LIST without any items that match the specified criteria. For example,
[LIST(apple,strawberry,pineapple,banana) => remove(CONTAIN:apple)]
The above would yield: strawberry,banana
PolyMatcher - a flexible way to perform text matching
In addition to extract text matching (or string matching), this command/expression also supports "polymatcher" (as of v3.6). With polymatcher, one can instruct Nexial to match the intended text in a less exact (but more expressiveness) way. Here are the supported matching strategies:
-
CONTAIN:: Use this technique to perform partial text matches. For example: useCONTAIN:completedas intent for "matching text that contains the text ‘completed’". -
CONTAIN_ANY_CASE:: Use this technique to perform partial text matches (same asCONTAIN:), except without considering the uppercase/lowercase variants. For example,CONTAIN_ANY_CASE:Successfullywould match "Completed successfully", "Completed Successfully", and "COMPLETED SUCCESSFULLY". -
START:: Use this technique to perform "starts with" text matches. For example,START:Greetingsmatches any text starting with the text "Greetings". -
START_ANY_CASE:: Use this technique to perform "starts with" text matches without considering letter casing. For example,START_ANY_CASE:Greetingsmatches any text starting with the text "Greetings", "GREETINGS", "greetings", "greeTINGs", etc. -
END:: Use this technique to perform "ends with" text matches. For example,END:Please try again.matches any text that ends with the text "Please try again.". -
END_ANY_CASE:: Use this technique to perform "ends with" text matches without considering letter casing. For example,END_ANY_CASE:Please try again.matches any text that ends with the text "Please try again." in any combination of upper or lower case. -
REGEX:: Use this technique to perform text matching via regular expression. For example: useREGEX:.+[S|s]uccessfully.*as intent for "matching text that contains 1 or more character, then either ‘Successfully’ or ‘successfully’, follow by zero or more characters.". -
EMPTY:[true|false]: Use this technique to perform "is empty?" check.EMPTY:truemeans that the target value is expected to be empty (no content or length).EMPTY:falsemeans the target value is expected NOT to be empty (with content). -
BLANK:[true|false]: Use this technique to perform "is blank?" check.BLANK:truemeans that the target value is expected to contain blank(s) or whitespace (space, tab, newline, line feed, etc.) characters or empty (no content or length).BLANK:falsemeans the target value is expected to contain at least 1 non-whitespace character. Note that this matcher includes teEMPTY:check as well. -
LENGTH:: Use this technique to perform text length validation against target value. One may use a numeric comparator for added flexibility/expressiveness. For example:LENGTH:5means to match the target value to a length of 5.LENGTH: > 5means to match the target value to a length greater than 5. The available comparators are:>,>=,<,<=,=,!=. -
NUMERIC:: Use this technique to perform numeric comparison/matching against target value. With this technique,100considered the same as100.00since both value has the same numerical value. One may use a numeric comparator for added flexibility/expressiveness. For example:NUMERIC:5means to match the target value to the number5.NUMERIC: <= -15.02means to match the target value as a number that is less or equal to-15.02. The available comparators are:>,>=,<,<=,=,!=. -
EXACT:: Use this to perform exact text matching, i.e. equality matching. In most cases, this is not required as the absence of any special keyword almost always means the "is this the same as that?" test. However in some special cases such as base »assertMatch(text,regex), one may use thisEXACT:syntax to indicate match by equality instead of regular expression. - And, of course, one can still use the exact matching strategy by specifying the exact text to match.
We will be adding new strategy to polymatcher – Please feel free to request for new ones!
replace(searchFor,replaceWith)
For the portion of all items that matches searchFor, replace it with replaceWith.
Example
Script:

Output:

replaceItem(searchFor,replaceWith)
Replace all items that exactly matches searchFor with replaceWith. For example, list =
CA,NY,AL,AK,HI,CA,AS,KR,CT,CS,CS,CA. [LIST($list) => replaceItem(CA,TX)] would return a list as
TX,NY,AL,AK,HI,TX,AS,KR,CT,CS,CS,TX.
Example
Script:

Output:

replaceRegex(searchFor,replaceWith)
Replace the content of all items that match the regular expression searchFor, with replaceWith.
Note that the parenthesis and commas characters could be a little tricky to handle since they are grammatically
significant as parameter boundary and parameter separator, respectively. One should use the backslash character (\) to
“escape” parenthesis and commas. In addition, parenthesis and various punctuations such as [, ], -, {, }, ?
and * are significant in the context of regular expression. To circumvent this possible confusion, one might need to
“double escape” certain characters when expressing a regular expression as an operation parameter, as in \\(US.+\\).
Example
Script:

Output:

replica(count)
Transform the current list to multiple copies of itself (append the list to itself). The count is used to specify the
number of times to repeat. For example, [LIST(a,b,c) => replica(2)] would yield a list of a,b,c,a,b,c,a,b,c.
Example
Script:

Output:

replicaUntil(size)
Transform the current list to multiple copies of itself (append the list to itself), until the length of the list is
the same as size. For example, [LIST(a,b,c) => replicaUntil(7)] would yield a list of a,b,c,a,b,c,a.
Example
Script:

Output:

retain(match)
Retain all the items from the list that match the specified match criteria. This operation utilizes polymatcher
(below) to determine the matching items. The result is a LIST with only items that match the specified criteria. For
example,
[LIST(apple,strawberry,pineapple,banana) => retain(CONTAIN:apple)]
The above would yield: apple,pineapple
PolyMatcher - a flexible way to perform text matching
In addition to extract text matching (or string matching), this command/expression also supports "polymatcher" (as of v3.6). With polymatcher, one can instruct Nexial to match the intended text in a less exact (but more expressiveness) way. Here are the supported matching strategies:
-
CONTAIN:: Use this technique to perform partial text matches. For example: useCONTAIN:completedas intent for "matching text that contains the text ‘completed’". -
CONTAIN_ANY_CASE:: Use this technique to perform partial text matches (same asCONTAIN:), except without considering the uppercase/lowercase variants. For example,CONTAIN_ANY_CASE:Successfullywould match "Completed successfully", "Completed Successfully", and "COMPLETED SUCCESSFULLY". -
START:: Use this technique to perform "starts with" text matches. For example,START:Greetingsmatches any text starting with the text "Greetings". -
START_ANY_CASE:: Use this technique to perform "starts with" text matches without considering letter casing. For example,START_ANY_CASE:Greetingsmatches any text starting with the text "Greetings", "GREETINGS", "greetings", "greeTINGs", etc. -
END:: Use this technique to perform "ends with" text matches. For example,END:Please try again.matches any text that ends with the text "Please try again.". -
END_ANY_CASE:: Use this technique to perform "ends with" text matches without considering letter casing. For example,END_ANY_CASE:Please try again.matches any text that ends with the text "Please try again." in any combination of upper or lower case. -
REGEX:: Use this technique to perform text matching via regular expression. For example: useREGEX:.+[S|s]uccessfully.*as intent for "matching text that contains 1 or more character, then either ‘Successfully’ or ‘successfully’, follow by zero or more characters.". -
EMPTY:[true|false]: Use this technique to perform "is empty?" check.EMPTY:truemeans that the target value is expected to be empty (no content or length).EMPTY:falsemeans the target value is expected NOT to be empty (with content). -
BLANK:[true|false]: Use this technique to perform "is blank?" check.BLANK:truemeans that the target value is expected to contain blank(s) or whitespace (space, tab, newline, line feed, etc.) characters or empty (no content or length).BLANK:falsemeans the target value is expected to contain at least 1 non-whitespace character. Note that this matcher includes teEMPTY:check as well. -
LENGTH:: Use this technique to perform text length validation against target value. One may use a numeric comparator for added flexibility/expressiveness. For example:LENGTH:5means to match the target value to a length of 5.LENGTH: > 5means to match the target value to a length greater than 5. The available comparators are:>,>=,<,<=,=,!=. -
NUMERIC:: Use this technique to perform numeric comparison/matching against target value. With this technique,100considered the same as100.00since both value has the same numerical value. One may use a numeric comparator for added flexibility/expressiveness. For example:NUMERIC:5means to match the target value to the number5.NUMERIC: <= -15.02means to match the target value as a number that is less or equal to-15.02. The available comparators are:>,>=,<,<=,=,!=. -
EXACT:: Use this to perform exact text matching, i.e. equality matching. In most cases, this is not required as the absence of any special keyword almost always means the "is this the same as that?" test. However in some special cases such as base »assertMatch(text,regex), one may use thisEXACT:syntax to indicate match by equality instead of regular expression. - And, of course, one can still use the exact matching strategy by specifying the exact text to match.
We will be adding new strategy to polymatcher – Please feel free to request for new ones!
reverse
Reverse the order of the items in the list.
Example
Script:

Output:

saveItems(indexAndVar)
Extract one or more items from current LIST and assign them to corresponding data variables. The item index and the corresponding target variable are expressed as name/value pairs separated by comma, like this:
[LIST(${list}) => ... saveItems(0=var1,1=var2,2=var3,...) ...]
The index is 0-based. As such, saveItems(1=FirstName,2=LastName) means save the 2nd item of the current LIST to a
data variable named FirstName, and the 3rd item of the current LIST to a data variable named LastName. Any invalid
index references, such as a number less than 0 or greater than the length of current LIST, are ignored.
Example
Script:
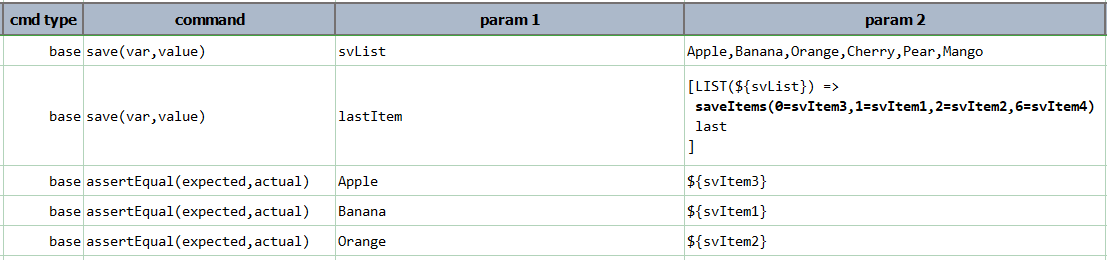
size
Same as length.
store(var)
Save current LIST expression to a data variable. If the specified var exists, its value will be overwritten. Using
this operation, one can put an expression on pause and resume it at a later time.
Example
Script:

Here, the list is converted to text and then upper operation of TEXT is performed.
Output:

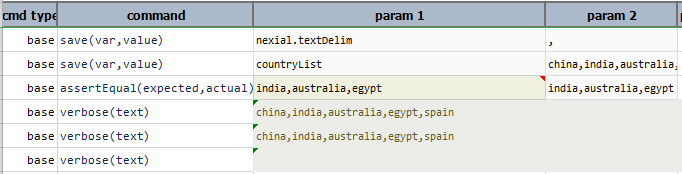
sublist(start,end)
Transform current list by downsizig it to a subset between start index and end index. Use -1 (or omit) for end
to signify the last position of the current list.
Example
Script:
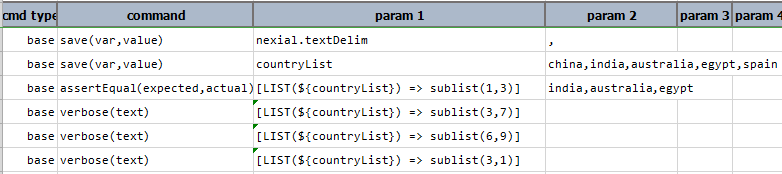
Here, sublist(1,3) returns the part of the list. The sublist(3,7) and sublist(6,9) returns the complete list as
the index (3,7) and (6,9) are invalid. The sublist(3,1) is also an invalid statement and returns empty string as
the start is greater than the end (3>1).
Output:
sum
Add up all the numbers found in the list as a NUMBER. Depending on the numbers found, the
resulting number (the sum) could be a whole or decimal number.
Example
Script:

Output:

text
Transform list into text using current text delimiter (denoted via
nexial.textDelim) as separator between item list items.
Example
Script:

Output:

union(list)
Transform the current list by appending to it the items in the specified list that are not found. In essence,
this operation creates a new list that contains all the items in both list without any repeats. See
Union (set theory)
for more details.
Example
Script:

Output:
