TEXT
Description
TEXT, as the name suggest, treats its input as text. All its operations treat their respective input as text as well.
Operations
after(text)
Retain the portion of text after the specified text.
Example
Script:

Output:

append(text)
Add one or more text to the end of text. Multiple texts can be passed in by separating them with a comma. For example
append(text1, text2, text3, ...)
Example
Script:

Output:

appendIfMissing(text)
Add text to the end of current text ONLY if text is currently not at the end of text.
Example
Script:

Output:

base64decode
BASE64 decode text.
Example
Script:

Output:

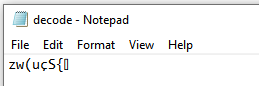
base64decodeThenSave(path,append)
Or, base64decode-then-save(path,append).
BASE64 decode current TEXT content and saving the decoded bytes to file specified via path. This operation assumes
that current TEXT content is BASE64 encoded, and that the decoded content is binary (e.g. Excel, PDF or Image file).
Use append to append the decoded content to an existing file.
Example
Script:

Output:

Saving the decoded bytes to the path specified in the file parameter.
decode.txt:
base64encode
BASE64 encode text.
Example
Script:

Output:

before(text)
Retain the portion of text before the specified text.
Example
Script:

Output:

between(before,after)
Retain the portion of text that is between the specified before and after text.
Example
Script:

Output:

binary
Convert current text into a BINARY expression. Generally speaking, a
BINARY expression by itself isn’t very useful. One can use its
save(path) operation to persist binary data into an external file.
Example
Script:

count(searchFor)
Transfer into a NUMBER data type that contains the number of occurrence for searchFor.
Example
Script:

Output:

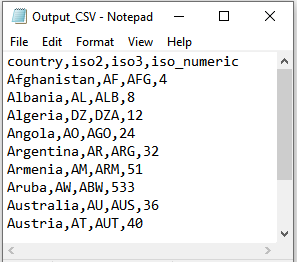
csv(positions)
Converts the given text content to csv format, separated by the given position numbers for each line specified via positions.
Example
Text input could be a text itself or a path to text file.
Text Input:
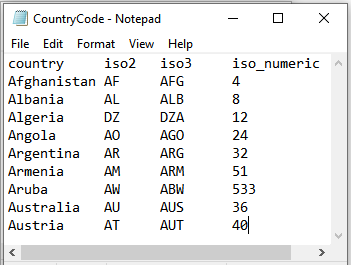
Script:

Output:
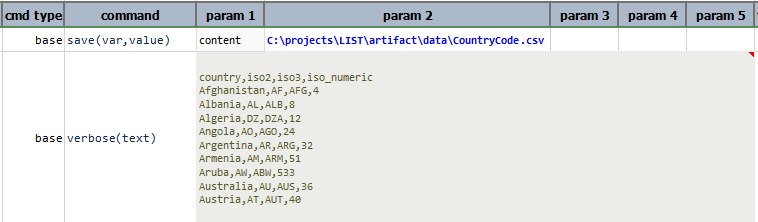
In this example, after converting to csv format, it saves the csv content to the given output file path.
Text Output:
distinct
Remove any duplicate characters from text.
Example
Script:

Output:

extract(beginRegex,endRegex,inclusive)
Extract from current text all instances of text found between beginRegex and endRegex. Both beginRegex and
endRegex are regular expressions. Set inclusive as true to include the text that matches beginRegex and
endRegex. This operation effectively transforms current TEXT expression into a LIST expression.
Example
Script:

Output:

ifContain(test,match,notMatch)
Also known as if-contain(test,match,notMatch). This operation replaces value of the current TEXT expression to either
match or notMatch, based on whether the value of the current TEXT expression contains test or not.
In other word,
- if current TEXT expression has a value that contains
test, then its value is replaced withmatch. - if current TEXT expression has a value that DOES NOT contain
test, then its value is replaced withnotMatch.
Example
Script:
[TEXT(Hello) => if-contain(ell,Hi,Bye)]
Output:
Hi
ifEqual(test,match,notMatch)
Also known as if-equal(test,match,notMatch). This operation replaces value of the current TEXT expression to either
match or notMatch, based on whether the value of the current TEXT expression is equal to test or not.
In other word,
- if current TEXT expression has a value equal to
test, then its value is replaced withmatch. - if current TEXT expression has a value NOT equal to
test, then its value is replaced withnotMatch.
Example
Script:
[TEXT(Hello) => if-equal(Hello,Bye,Huh?)]
Output:
Bye
ifMatch(regex,match,notMatch)
Also known as if-match(test,match,notMatch). This operation replaces value of the current TEXT expression to either
match or notMatch, based on whether the value of the current TEXT expression satisfies the specified regex in
its entirety or not.
In other word,
- if current TEXT expression has a value that matches
regex, then its value is replaced withmatch. - if current TEXT expression has a value that DOES NOT match to
regex, then its value is replaced withnotMatch.
Example
Script:
[TEXT(Catepillar) => if-match(^.+pills.+$,Butterfly,Medicine)]
Output:
Medicine
insert(after,text)
Search for after in text, and if found, add the specified text to it. If after is not found, no changes will be
made to text.
Example
Chain up a remove and a insert. In this example, after removing the word “all”, insert operation will insert
“each and every” after the word “for”.
Script:

Output:

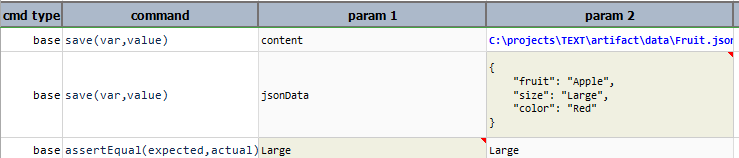
json
Transform existing text into a JSON expression. If
nexial.expression.resolveURL is set to true and the current
text content is a URL, Nexial will automatically download from such URL and transform the download content as
JSON expression. Internally, Nexial will also apply
content sanitization to improve the likelihood of deriving an usable JSON document.
Example
In this example, the text is converted to json format, to perform json operations on it.
Script:

Output:
leftMost(length)
Or left-most(length). Truncate the current TEXT value FROM THE LEFT so that its length is equal or less to
length. If the current TEXT value has a length less than length, then it will remain unchanged.
Example
Script:
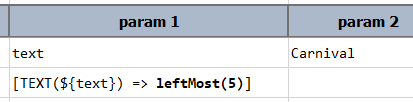
This will print to the console:
Carni
length
Transfer into a NUMBER data type that contains the length of text.
Example
Script:

Output:

list(delim)
Transfer into a LIST data type by converting text into a list, using delim as the character to split.
Example
Script:

Output:

lower
Turn text into lowercase equivalent.
Example
Script:

Output:

normalize
Remove any leading or trailing whitespaces and also remove duplicate whitespace characters in text. The end result is that text will not contain any occurrences of successive spaces.
Example
Script:

Output:

number
Transfer into a NUMBER data type by converting text into a numeric value. Failure to explicitly
convert text into number will result in an ERROR condition.
Example
Script:

Output:

pack
Remove all whitespace characters (tab, space, line feed, carriage return) from text.
Example
Script:

Output:

padLeft(padWith,maxLength)
Or pad-left(padWith,maxLength). Pad (add) existing text with padWith character(s) from the left, until
maxLength length is reached. If current TEXT expression value already exceeds specified maxLength, it will be
truncated (from the right) to maxLength.
Example
Script:

This will print out the following on the console:
......John
padRight(padWith,maxLength)
Or pad-right(padWith,maxLength). Pad (add) existing text with padWith character(s) from the right, until
maxLength length is reached. If current TEXT expression value already exceeds specified maxLength, it will be
truncated (from the right) to maxLength.
Example
Script:

This will print out the following on the console:
John------
parseAsCsv(configs)
Parse the current text content as CSV. This operation supports the same parsing options found in
CSV » parse(configs).
Example
In this example, the parseAsCsv(configs) operation is invoked on a TEXT expression. The next operation, store(var),
is issued against the now-transformed CSV expression. This is evident by the fact that the subsequent operation is
column-count, which is an operation from CSV Expression. Furthermore, the “stored” data variable is
recalled in the next command as a CSV expression, from which the row-count operation is issued.
Script:

prepend(text)
Add one or more text to the beginning of current text.
Example
Script:

Output:

prependIfMissing(text)
Add text to the beginning of current text ONLY if text if currently not at the beginning of text.
Example
Script:

Output:

remove(text)
Remove any and all occurrences of text.
Example
Script:

Output:

removeEnd(ending)
Or remove-end(ending). Remove ending character sequence (substring) of text that matches ending.
Example
Script:

Output:

removeLeft(length)
Or remove-left(length). Use length to specify the number of characters to remove from the left (i.e. the
beginning) of the text. The parameter length must be a positive integer. If length is greater than the length of
current text, an empty text will be returned.
Example
Script:

Output:

removeLines(match)
Remove lines from current expression that matches the specified match. This operation supports PolyMatcher.
PolyMatcher - a flexible way to perform text matching
In addition to extract text matching (or string matching), this command/expression also supports "polymatcher" (as of v3.6). With polymatcher, one can instruct Nexial to match the intended text in a less exact (but more expressiveness) way. Here are the supported matching strategies:
-
CONTAIN:: Use this technique to perform partial text matches. For example: useCONTAIN:completedas intent for "matching text that contains the text ‘completed’". -
CONTAIN_ANY_CASE:: Use this technique to perform partial text matches (same asCONTAIN:), except without considering the uppercase/lowercase variants. For example,CONTAIN_ANY_CASE:Successfullywould match "Completed successfully", "Completed Successfully", and "COMPLETED SUCCESSFULLY". -
START:: Use this technique to perform "starts with" text matches. For example,START:Greetingsmatches any text starting with the text "Greetings". -
START_ANY_CASE:: Use this technique to perform "starts with" text matches without considering letter casing. For example,START_ANY_CASE:Greetingsmatches any text starting with the text "Greetings", "GREETINGS", "greetings", "greeTINGs", etc. -
END:: Use this technique to perform "ends with" text matches. For example,END:Please try again.matches any text that ends with the text "Please try again.". -
END_ANY_CASE:: Use this technique to perform "ends with" text matches without considering letter casing. For example,END_ANY_CASE:Please try again.matches any text that ends with the text "Please try again." in any combination of upper or lower case. -
REGEX:: Use this technique to perform text matching via regular expression. For example: useREGEX:.+[S|s]uccessfully.*as intent for "matching text that contains 1 or more character, then either ‘Successfully’ or ‘successfully’, follow by zero or more characters.". -
EMPTY:[true|false]: Use this technique to perform "is empty?" check.EMPTY:truemeans that the target value is expected to be empty (no content or length).EMPTY:falsemeans the target value is expected NOT to be empty (with content). -
BLANK:[true|false]: Use this technique to perform "is blank?" check.BLANK:truemeans that the target value is expected to contain blank(s) or whitespace (space, tab, newline, line feed, etc.) characters or empty (no content or length).BLANK:falsemeans the target value is expected to contain at least 1 non-whitespace character. Note that this matcher includes teEMPTY:check as well. -
LENGTH:: Use this technique to perform text length validation against target value. One may use a numeric comparator for added flexibility/expressiveness. For example:LENGTH:5means to match the target value to a length of 5.LENGTH: > 5means to match the target value to a length greater than 5. The available comparators are:>,>=,<,<=,=,!=. -
NUMERIC:: Use this technique to perform numeric comparison/matching against target value. With this technique,100considered the same as100.00since both value has the same numerical value. One may use a numeric comparator for added flexibility/expressiveness. For example:NUMERIC:5means to match the target value to the number5.NUMERIC: <= -15.02means to match the target value as a number that is less or equal to-15.02. The available comparators are:>,>=,<,<=,=,!=. -
EXACT:: Use this to perform exact text matching, i.e. equality matching. In most cases, this is not required as the absence of any special keyword almost always means the "is this the same as that?" test. However in some special cases such as base »assertMatch(text,regex), one may use thisEXACT:syntax to indicate match by equality instead of regular expression. - And, of course, one can still use the exact matching strategy by specifying the exact text to match.
We will be adding new strategy to polymatcher – Please feel free to request for new ones!
removeRegex(regex,options)
Remove character(s) that matches regex.
Optionally, one can specify two options multiLine, caseSensitivity. Both the parameters are optional.
multiLine:-trueto support text content that spans across multiple lines. Default value set totrue. This MUST BE FIRST PARAMETER after regex. When enabling the multi-line mode, be sure to start theregexwith a^character to signify the start of a line, and to end theregexwith a\ncharacter (not$) to represent the end of line.caseSensitivity: By default, this operation will perform regular expression pattern matching case-sensitively. One can set thecaseSensitiveparameter asfalseto enforce a case-insensitive pattern matching. Default value set tofalse. This MUST BE SECOND PARAMETER after regex, immediately aftermultiLine.
Example
Script:

Output:

removeRight(length)
Or remove-right(length). Use length to specify the number of characters to remove from the right (i.e. the
end) of the text. The parameter length must be a positive integer. If length is greater than the length of current
text, an empty text will be returned.
Example
Script:

Output:

removeStart(start)
Or remove-start(start)
Remove starting character sequence (substring) of text that matches start.
Example
Script:

Output:

repeat(times)
Transform current TEXT expression by repeating its text value. The number of repeats is controlled via the times
parameter. Note that if times is not a positive number, this expression would contain empty text (i.e. no value).
replace(searchFor,replaceWith)
As the name suggest, this operation will search for searchFor and replace matches with replaceWith.
Example
Script:

Output:

replaceRegex(regexSearch,replaceWith)
Perform a regex-search on text using regexSearch and replace all matches with replaceWith. Note that grouping
character ( and ) should be escaped as \(...\). For example, [TEXT(...) => replaceRegex(\(chicken\),beef)]
Example
Script:

Output:

retain(keep)
Retain only the characters found in keep.
Example
Script:

Output:

retainRegex(regex)
Or retain-regex(regex). Retain only the characters matched to regex.
Example
Script:

Output:

rightMost(length)
Or right-most(length). Truncate the current TEXT value so that its length is equal or less to length. If the
current TEXT value has a length less than length, then it will remain unchanged.
Example
Script:

This will print to the console:
enture
save(path,append)
Save current text content to path. If path resolves to an existing file, append set as true will append
current text content to the said file. append is optional and defaults to false.
Example
Script:

Output:

In this example, “Now is the time for all good people to come to the aid of his country.” is saved to the given
path, after the execution of next test step “Actions speak louder than words.” is appended after the content of
first line as append is set to true.

store(var)
Save current TEXT expression to a data variable. If the specified var exists, its value will be overwritten. Using
this operation, one can put an expression on pause and resume it at a later time.
Example
Script:

Output:

substring(start,end)
Retain the portion of text from the start position (zero-based) to the end position (exclusive).
Example
Script:

Output:

swapCases
Or swap-cases. Convert the current TEXT expression by swapping the upper and title case to lower case, and lower case to upper case.
Example
[TEXT(Hello World!) => swapCases]
would yield
hELLO wORLD!
text
Retrieve the text from this Text Expression.
title
Turn text into Title Case, while the first letter of every word is capitalized.
Example
Script:

Output:

trim
Remove any non-printable character in the beginning or ending of text.
Example
Script:

Output:

upper
Turn text into UPPERCASE equivalent.
Example
Script:

Output:

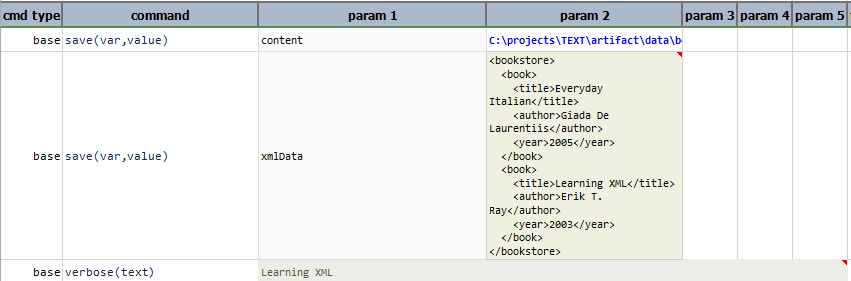
xml
Transform existing text into a XML expression. If
nexial.expression.resolveURL is set to true and the current
text content is a URL, Nexial will automatically download from such URL and transform the download content as
XML expression. One may use this operation to parse the HTML content as a XML document.
Example
In this example, the text is converted to xml format, to perform xml operations on it.
Suppose the following XML document bookStore.xml:
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book>
<title>Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
</book>
<book>
<title>Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
</book>
</bookstore>
Script:

Output: